Gemma4에서 MTP를 켜면 얼마나 빨라질까?
이번 실험의 출발점은 단순했다. Gemma4에서 MTP(Multi-Token Prediction)를 켜면 실제로 얼마나 빨라질까? 12B 모델에서 먼저 no-MTP와 MTP를 비교했고, 속도가 꽤 빨라지는 것을 확인했다. 그래서 같은 방식으로 26B에도 MTP를 켜서 비교해봤다.
이 실험의 직접적인 계기는 Unsloth가 X에 올린 Gemma 4 MTP GGUF 안내였다. Unsloth는 Gemma 4가 MTP GGUF로 더 빠르게 동작한다고 소개했고, 자세한 실행 방법은 Unsloth의 MTP 문서에 정리되어 있었다. 문서에서는 MTP가 여러 미래 토큰을 제안하고 main model이 검증하는 방식이며, Gemma 4 GGUF에서 대략 1.4배에서 2.2배 정도의 속도 향상을 기대할 수 있다고 설명한다. 이 숫자가 내 DGX Spark 환경에서도 실제로 나오는지 확인해보고 싶었다.
그런데 실험을 진행하다 보니 중요한 변수가 하나 있었다. Gemma4 26B는 일반적인 dense 26B가 아니라 26B-A4B MoE 모델이었다. 즉 전체 파라미터는 26B급이지만 토큰마다 활성화되는 계산량은 약 4B 수준이다. 그래서 26B에서 MTP 효과가 작게 나온 것이 단순한 런타임 문제인지, 아니면 MoE 구조 때문인지 보기 위해 MoE가 아닌 31B Dense도 추가로 테스트했다.
따라서 이 글의 중심은 “어떤 모델이 최고인가?”가 아니다. 결론을 하나로 내리기보다는, MTP를 켰을 때 속도가 얼마나 오르고, 그 효과가 dense와 MoE 구조에서 어떻게 다르게 보였는지를 정리하는 글이다.
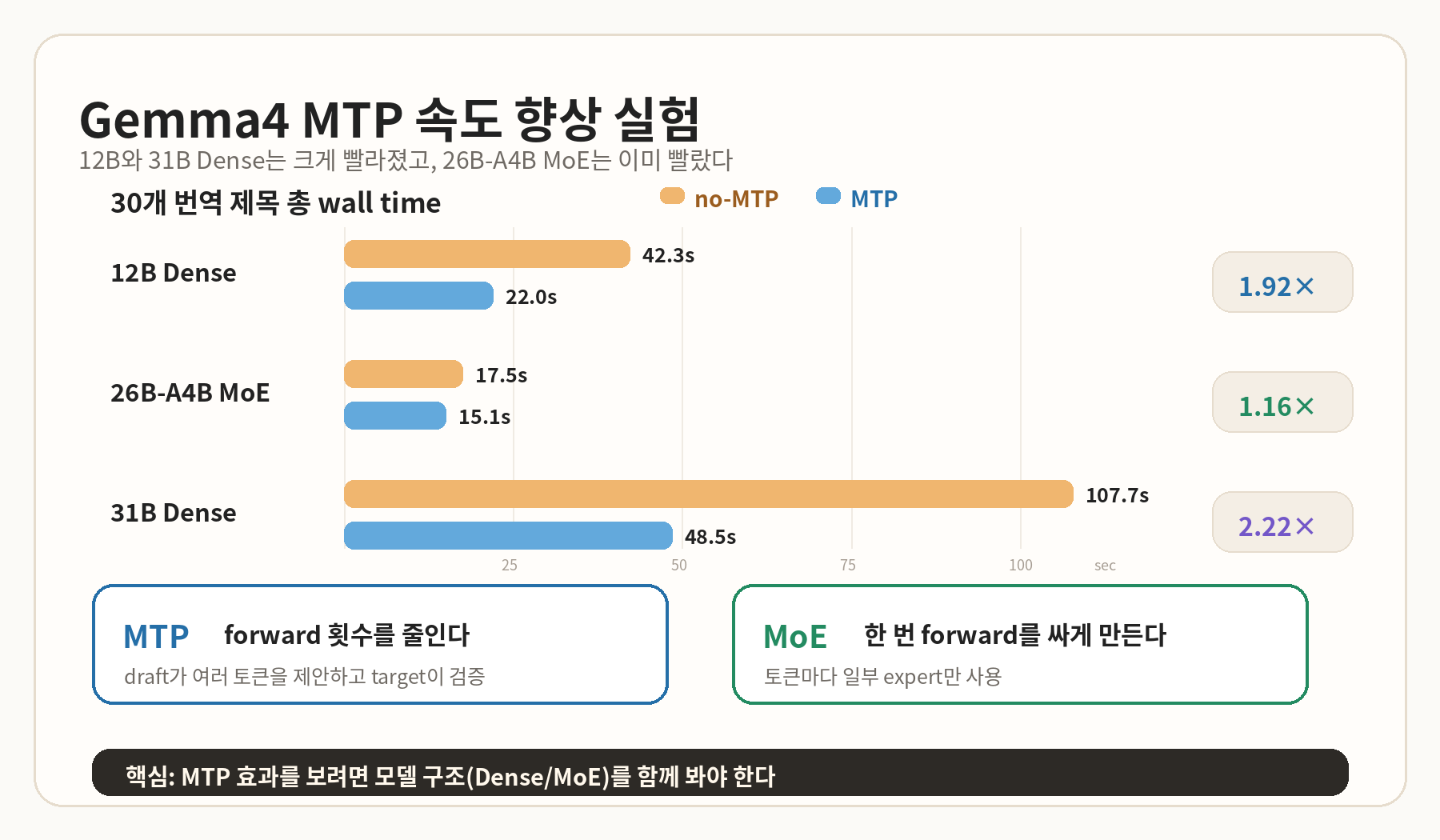
핵심 관찰: Dense 모델에서는 MTP 속도 향상이 컸고, 26B-A4B MoE에서는 이미 기본 속도가 빨라 MTP 추가 효과가 상대적으로 작았다.
실험 대상
비교한 모델은 다음과 같다.
| 모델 | 구조 | 파일/런타임 | 비고 |
|---|---|---|---|
| Gemma4 12B Q8 | Dense | gemma-4-12B-it-Q8_0.gguf / llama.cpp | 처음 MTP 효과를 확인한 기준 모델 |
| Gemma4 26B-A4B Q8 | MoE | gemma-4-26B-A4B-it-Q8_0.gguf / llama.cpp | 26B급이지만 active 약 4B |
| Gemma4 31B Q8 | Dense | gemma-4-31B-it-Q8_0.gguf / llama.cpp | MoE가 아닌 대형 dense 비교군 |
테스트셋은 이전 글에서 썼던 것과 같은 일본어·영어·중국어 테크/개발/AI 관련 제목 30개다. 모든 모델에 같은 번역 프롬프트를 넣고, no-MTP와 MTP 결과를 비교했다. 품질은 출력이 달라진 항목만 GPT-5.5 judge로 확인했다.
실행 환경은 DGX Spark 계열 서버였다. 12B와 31B Dense, 26B-A4B의 GGUF 모델은 spark 또는 spark2에서 llama.cpp CUDA server로 띄웠고, OpenAI 호환 API로 같은 번역 요청을 보냈다. 모델 파일은 Q8 GGUF를 사용했으며, MTP 테스트에서는 별도의 MTP GGUF를 --model-draft로 지정하고 --spec-type draft-mtp를 켰다. 따라서 이 결과는 노트북이나 Mac 로컬 실행 결과가 아니라, DGX Spark 서버 환경에서의 실사용 벤치마크로 보는 것이 맞다.
속도 결과
| 모델 | 구조 | no-MTP 총 시간 | MTP 총 시간 | wall speedup | predicted tok/s speedup | draft accept |
|---|---|---|---|---|---|---|
| Gemma4 12B Q8 | Dense | 42.26s | 21.98s | 1.92x | 2.35x | 51.8% |
| Gemma4 26B-A4B Q8 | MoE | 17.53s | 15.05s | 1.16x | 1.33x | 49.8% |
| Gemma4 31B Q8 | Dense | 107.72s | 48.45s | 2.22x | 2.91x | 58.2% |
가장 먼저 눈에 띈 것은 12B Dense에서 MTP가 거의 2배 가까운 속도 향상을 보였다는 점이다. 이게 이번 실험의 시작점이었다. 짧은 제목 번역 30개 기준으로 총 wall time이 42.26초에서 21.98초로 줄었다.
그 다음 26B-A4B에서도 같은 테스트를 했는데, 결과는 달랐다. MTP를 켜도 17.53초에서 15.05초로 줄어드는 정도였다. 속도 향상이 없었던 것은 아니지만, 12B에서 본 것처럼 극적인 차이는 아니었다.
여기서 “26B라서 그런가?”라는 질문이 생겼다. 하지만 26B-A4B는 MoE 모델이다. 그래서 MoE가 아닌 대형 dense 모델인 31B도 추가로 테스트했다. 31B Dense에서는 no-MTP 107.72초가 MTP 48.45초로 줄었다. 다시 2배 이상 빨라진 것이다.
12B Dense: 42.26s → 21.98s (1.92x)
26B-A4B MoE: 17.53s → 15.05s (1.16x)
31B Dense: 107.72s → 48.45s (2.22x)품질 변화
속도만 빨라지고 번역 품질이 흔들리면 의미가 없다. 그래서 no-MTP와 MTP의 출력 차이도 확인했다.
| 모델 | 완전 동일 | 차이 있음 | 달라진 항목의 GPT-5.5 judge 결과 |
|---|---|---|---|
| 12B Dense no-MTP vs MTP | 12/30 | 18/30 | MTP 12, no-MTP 6 |
| 26B-A4B no-MTP vs MTP | 25/30 | 5/30 | MTP 4, no-MTP 1 |
| 31B Dense no-MTP vs MTP | 29/30 | 1/30 | MTP 1 |
이 벤치에서는 MTP를 켰다고 품질이 나빠졌다고 보기는 어려웠다. 12B는 출력 차이가 꽤 있었지만, judge 결과는 오히려 MTP 쪽이 더 많이 선택됐다. 26B-A4B와 31B Dense는 출력 자체가 대부분 같았다. 특히 31B Dense는 30개 중 29개가 글자까지 완전히 같았다.
물론 이 결과를 “MTP는 어떤 상황에서도 품질 영향이 없다”로 일반화하면 안 된다. 이번 테스트는 짧은 제목 번역 30개에 한정된 실사용 벤치다. 다만 적어도 이 범위에서는 MTP의 속도 향상이 품질 저하를 동반하지 않았다고 볼 수 있다.
왜 26B에서는 MTP 효과가 작았을까?
실험 중 가장 헷갈렸던 지점이 바로 여기였다. 처음에는 “26B에서도 MTP를 켜면 12B처럼 빨라지겠지”라고 기대했다. 그런데 26B-A4B는 이미 no-MTP 상태에서도 매우 빨랐다.
이유는 26B-A4B의 구조에 있다. 이 모델은 dense 26B가 아니라 MoE(Mixture of Experts)다. 전체 파라미터는 26B급이지만, 토큰 하나를 생성할 때 모든 파라미터가 계산되는 것이 아니라 일부 expert만 활성화된다. 이름의 A4B도 active 4B에 가까운 의미다.
즉 26B-A4B는 MTP를 켜기 전부터 이미 “한 번 forward할 때의 계산량”이 작다. 그래서 MTP를 추가로 켰을 때 얻는 이득이 dense 모델보다 작게 보였을 가능성이 크다.
MoE와 MTP는 어떻게 다른가?
MoE와 MTP는 둘 다 추론을 빠르게 만드는 데 관련이 있지만, 작동 위치가 다르다.
| 구분 | MoE | MTP |
|---|---|---|
| 적용 위치 | 모델 아키텍처 내부 | 추론/디코딩 방식 |
| 핵심 아이디어 | 토큰마다 일부 expert만 계산 | 여러 토큰 후보를 미리 제안하고 검증 |
| 줄이는 것 | 한 번 forward의 계산량 | 필요한 target forward 횟수 |
| 비유 | 한 번 계산을 싸게 만든다 | 계산 횟수를 줄인다 |
| 품질 영향 | 모델 구조 자체가 품질/성향에 영향 | 이론적으로는 target 모델 출력을 보존 |
Dense 모델은 토큰 하나를 만들 때 거의 전체 경로가 계산된다. 반면 MoE 모델은 라우터가 일부 expert를 고르고, 선택된 expert만 계산한다. MTP는 또 다르다. draft 또는 MTP head가 다음 토큰 여러 개를 제안하고, target 모델이 그 후보를 검증한다. 후보가 많이 맞으면 target 모델을 한 토큰씩 반복 호출하는 것보다 빠르다.
MoE = 한 번 forward를 싸게 만든다.
MTP = forward 횟수를 줄인다.그래서 26B-A4B에서도 MTP를 켤 수는 있다. 다만 이미 MoE 덕분에 한 번 forward가 싸기 때문에, dense 12B나 dense 31B에서 본 것만큼의 추가 이득은 나오지 않았다.
참고한 자료
- UnslothAI X 포스트: Gemma 4 MTP GGUF 안내 — 이번 실험을 시작하게 된 계기. Gemma 4가 MTP GGUF로 더 빨라진다는 내용과 예시 속도 수치가 소개되어 있었다.
- Unsloth Documentation: How to Run MTP Models — MTP의 개념, llama.cpp 실행 예시,
--spec-draft-n-max설정, Gemma 4 MTP 관련 안내를 참고했다.
정리
이번 실험의 결론은 “무조건 어떤 모델이 좋다”가 아니라, MTP 효과는 모델 구조에 따라 다르게 보인다는 것이다.
- 12B Dense에서는 MTP가 약 1.9배 속도 향상을 보였다.
- 26B-A4B MoE에서는 MTP 효과가 약 1.16배로 작았다.
- 31B Dense에서는 다시 약 2.2배 속도 향상이 나왔다.
- 이번 번역 제목 벤치에서는 MTP로 인한 품질 저하는 관찰되지 않았다.
- 26B-A4B의 작은 MTP 효과는 모델이 MoE 구조라 이미 빠른 것과 관련 있어 보인다.
따라서 이번 실험에서 가장 중요한 포인트는 이것이다.
MTP는 dense 모델에서 특히 큰 속도 향상을 보여줬다. 26B-A4B에서는 효과가 작았지만, 그건 26B가 느려서가 아니라 MoE 구조로 이미 빠르게 동작하기 때문으로 보인다.
이 정도가 지금까지의 실험으로 말할 수 있는 선이다. 어떤 모델을 기본으로 둘지는 실제 서비스에서 원하는 응답 속도, 메모리 사용량, 긴 문맥 품질, 작업 종류에 따라 따로 판단해야 한다.
Sun, 14 Jun 2026 16:30:00 +0900